1. 소개
데이터 시각화는 통찰력 생성에 중요한 도구지만 정확한 형식으로 데이터를 얻기 힘들기 떄문에 데이터 변환을 이용한다.
1.1. 전제조건
tidyverse의 또 다른 핵심 멤버 인 dplyr 패키지를 사용하는 방법에 초점을 맞춘 정리입니다.
nycflights13 패키지의 데이터를 사용하여 데이터 변환에 대한 정리 했습니다.
1 | library(nycflights13) |
1.2. nycflights13
이 데이터는 2013년 뉴욕에서 출발한 항공편의 데이터입니다.
1 | flights |
데이터 프레임의 아랫줄에 <>안에 들어가는 단어는 각변수의 데이터 유형을 뜻합니다.
- int -> 정수를 의미
- dbl -> 실수를 의미
- chr -> 문자열 의미
- dttm -> 날짜-시간 의미
1-3. dplyr의 기본사항
dplyr 함수에는 대부분의 데이터 조작 문제를 해결할 수 있는 5가지 주요함수가 있습니다.![]()
여기에 group_by() 함수를 추가로 이용하면 그룹별로 다양한 집계를 할 수 있습니다.
2. filter()
fliter()함수는 조건에 따라 행(row)를 추출한다.
- fliter()함수의 사용방법
- 첫번째 인수에 추출대상이 되는 데이터 프레임을 지정
- 두번쨰 인수에 추출하고싶은 행의 조건을 지정
아래의 데이터는 filter() 함수를 써서 1월1일의 정보만 추출한 것이다filter() 함수를 실행하면 dplyr은 필터링작업을 실행하고 적용한 조건에 맞는 새 데이터 프레임을 반환합니다1
2
3
4
5
6
7
8
9
10
11
12
13filter(flights, month == 1, day == 1)
#> # A tibble: 842 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # … with 836 more rows, and 11 more variables: arr_delay <dbl>, carrier <chr>,
#> # flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
filter() 함수는 dplyr의 특징과 마찬가지로 filter()함수를 이용해 추출한 결과값을 변수로 지정하지 않으면 그 값이 따로 저장되지 않으며, 원본 데이터를 변형시키지 않습니다.
- 예)
1
변수 <- filter(flights, month == 1, day == 1)
2.1. 비교
필터링을 효과적으로 사용하려면 비교연산자 와 논리연산자를 이해하고 적절하게 쓸수있어야합니다.
2.1.1 비교 연산자
비교연산자를 사용하여 원하는 조건을 구현할수 있는 방법을 알아야합니다.![]()
2.1.2 논리 연산자
논리 연산자에는 AND , OR , NOT 3가지가 있습니다
- 논리연산의 결과는 TRUE 와 FALSE 라는 진리값 입니다.
![]()
2.1.3 결측값
NA 는 값이 기록되지 않거나 관측되지 않은 경우 데어터에 저장되는 값으로 결측치(Missing Value)라고 한다.
- NA 유무 확인
- is.na() 를 사용하면 값이 누락되었는지 확인할수있다.
- in.na()는 백터의 결측지가 존재할경우 ture를 출력한다.
- ```
is.na(x)
#> [1] TRUE1
2
3
4
5
6
7* NA는 Missing Value를 표현하는 논리형 자료지만, "NA"는 문자열 그자체이기 떄문에 사용에 주의 해야한다.
- ```
is.na(NA)
#> [1] TRUE
is.na("NA")
#> [1] FALSE
- ```
3. arrange()
arrange()함수는 지정한 열을 기준으로 오름차순으로 정렬합니다.
- arrange()함수의 사용방법
- arrange(데이터 프레임, 열이름)
- 역순으로 정렬할 때는 desc()함수를 함께 사용합니다.
- arrange(데이터 프레임, desc(열이름))
- arrange()함수를 써서 값을받았을떄 누락된 값은 오름차순을 쓰나 내림차순을 쓰나 항상 끝에 정렬됩니다.
4. select()
select()함수는 데이터에 있는 수 많은 변수들 중 일부만 추출해서 쓸떄 사용한다
- select()함수의 사용방법
- select(데이터 프레임, 변수) -> 지정한 데이터 프레임에서 선택한 변수의 열(column)만 추출해서 보여준다.
- select(데이터 프레임, -변수) -> 지정한 데이터 프레임에서 선택한 변수를 제외한 나머지 열(column)을 추출해서 보여준다.
- select(데이터 프레임, 변수:변수) ->지정한 데이터 프레임에서 선택한 변수에서 부터 선택한 변수까지의 열(column)을 추출해서 보여준다.
5. mutate()
mutate()함수는 데이터 프레임에 새로운 열(column)을 만들거나 기존의 열(column)을 조건에 맞게 변경할떄 사용합니다.
mutate()를써서 새로 생성된 열(column)은 별도의 변수로 지정하거나 기존의 데이터에 덮어씌우지 않는한 저장되지는 않는다.
- mutate()함수의 사용법
- mutate(데이터 프레임, 새로운 column명 = 기존 columns을 조합한 수식)
6. summarise()
summarise()함수는 각종 통계함수와 함께 사용하여 데이터 프레임의 특정변수에 속한 값들을 하나의 통계값으로 요약하여 반환하는 함수입니다.
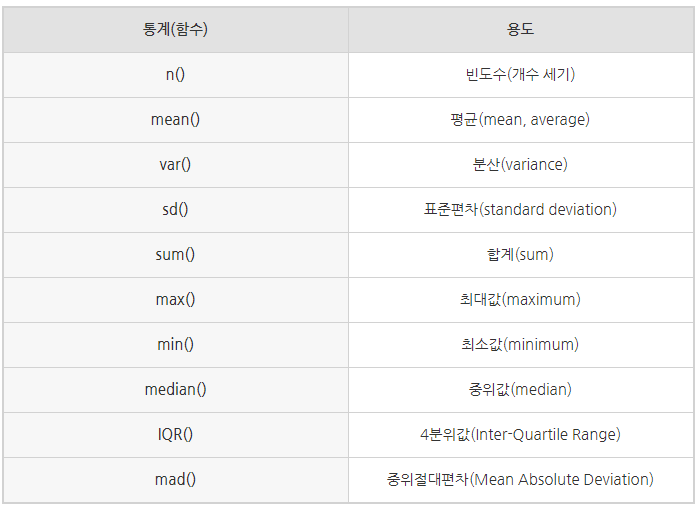
- summarise()와 함께 사용하는 주요 통계함수
-
- summarise()함수 사용법
- summarise(데이터프레임, 통계값담을column명 = 통계함수(통계값구할column))
- na.rm=TRUE
- 통계 계산시 NA값을 제외하고 계산한다.
- summarise(데이터프레임, 통계값담을column명 = 통계함수(통계값구할column, na.rm=TRUE))
- 통계 계산시 NA값을 제외하고 계산한다.
7. group_by()
특정 열을 기준으로 데이터프레임을 요약해서 봐야할경우(피벗 테이블을 만들고 싶을떄)쓴다.
- group_by()함수 사용법
- group_by(기준이되는 column) %>%
summarise(통계값담을column명 = 통계함수(통계값구할column))
- group_by(기준이되는 column) %>%